智能之眼,智造之基——揭秘機(jī)器人自動(dòng)化工廠的工業(yè)相機(jī)標(biāo)配

在當(dāng)今高度智能化、自動(dòng)化的現(xiàn)代工廠中,機(jī)器人已不再是孤立的執(zhí)行單元,而是一個(gè)協(xié)同、感知、決策的復(fù)雜系統(tǒng)。驅(qū)動(dòng)這一系統(tǒng)精準(zhǔn)、高效運(yùn)行的核心感官之一,便是被譽(yù)為“機(jī)器之眼”的工業(yè)相機(jī)。它不僅賦予機(jī)器人“看見(jiàn)”的能力,更是實(shí)現(xiàn)質(zhì)量控制、精密引導(dǎo)、智能識(shí)別等高端應(yīng)用不可或缺的標(biāo)配。一個(gè)真正高大上的機(jī)器人自動(dòng)化工廠,其工業(yè)相機(jī)的配置堪稱一門精密的藝術(shù)。
一、 標(biāo)配核心:多元化的相機(jī)類型與配置
- 2D視覺(jué)系統(tǒng):基礎(chǔ)與基石
- 高速面陣相機(jī):用于快速的產(chǎn)品外觀檢測(cè)、條碼/二維碼讀取、裝配完整性驗(yàn)證等。在高節(jié)拍的生產(chǎn)線上,毫秒級(jí)的成像速度與高分辨率是保障效率與質(zhì)量的關(guān)鍵。
- 線陣相機(jī):專為連續(xù)運(yùn)動(dòng)或大幅面物體設(shè)計(jì),如卷材、薄膜、金屬板的表面缺陷檢測(cè)。它與產(chǎn)線速度完美同步,實(shí)現(xiàn)無(wú)縫掃描,是連續(xù)生產(chǎn)質(zhì)量控制的核心。
- 3D視覺(jué)系統(tǒng):賦能深度感知與引導(dǎo)
- 激光輪廓掃描儀(3D線激光):通過(guò)激光線掃描物體表面,獲取高精度的三維輪廓數(shù)據(jù)。這是機(jī)器人無(wú)序抓取(Bin Picking) 的絕對(duì)標(biāo)配。它能幫助機(jī)器人在雜亂無(wú)章的料箱中,精準(zhǔn)識(shí)別、定位并抓取任意姿態(tài)的工件,極大提升了生產(chǎn)柔性。
- 結(jié)構(gòu)光3D相機(jī):通過(guò)投射特定光斑圖案并分析變形來(lái)重建三維模型。適用于精密測(cè)量、三維尺寸檢測(cè)、焊接引導(dǎo)(尤其是焊縫跟蹤)以及高精度裝配驗(yàn)證,為機(jī)器人提供了毫米級(jí)甚至微米級(jí)的空間定位能力。
二、 超越“看見(jiàn)”:集成化的智能視覺(jué)解決方案
高大上的工廠不僅配備相機(jī)硬件,更將其深度集成,形成智能視覺(jué)解決方案:
- 機(jī)器人視覺(jué)引導(dǎo)(VS)系統(tǒng):這是工業(yè)相機(jī)最經(jīng)典的應(yīng)用。通過(guò)2D或3D相機(jī)實(shí)時(shí)獲取目標(biāo)位置與姿態(tài),引導(dǎo)機(jī)器人完成精準(zhǔn)的拾取、放置、裝配、涂膠、焊接等動(dòng)作,補(bǔ)償了工件位置、夾具的誤差,實(shí)現(xiàn)了真正的柔性生產(chǎn)。
- 在線視覺(jué)檢測(cè)(AVI)系統(tǒng):替代人眼,進(jìn)行7x24小時(shí)無(wú)間斷、客觀、一致的質(zhì)量檢測(cè)。涵蓋尺寸測(cè)量、缺陷檢測(cè)(劃痕、污損、毛刺)、顏色分辨、字符識(shí)別等。它不僅是質(zhì)量的“守門員”,更能通過(guò)數(shù)據(jù)統(tǒng)計(jì)為工藝優(yōu)化提供依據(jù)。
- 智能讀碼與追溯系統(tǒng):在物流、裝配線關(guān)鍵工位部署高分辨率讀碼相機(jī),快速、準(zhǔn)確地讀取各類一維碼、二維碼乃至DPM碼(直接零件標(biāo)識(shí)),實(shí)現(xiàn)產(chǎn)品全生命周期的數(shù)據(jù)追溯,是構(gòu)建數(shù)字化透明工廠的基石。
三、 高大上的隱形標(biāo)配:性能與可靠性
- 卓越的工業(yè)級(jí)可靠性:真正的標(biāo)配意味著能適應(yīng)嚴(yán)苛的工廠環(huán)境:防塵防水(IP67等級(jí)常見(jiàn))、抗振動(dòng)、寬溫域工作(-5°C至45°C甚至更廣)、抗電磁干擾,確保7x24小時(shí)穩(wěn)定運(yùn)行。
- 強(qiáng)大的軟件與算法平臺(tái):相機(jī)背后,是強(qiáng)大的機(jī)器視覺(jué)軟件(如Halcon, VisionPro, 或國(guó)產(chǎn)優(yōu)秀平臺(tái))和深度學(xué)習(xí)(AI)算法。它們讓相機(jī)不僅能“拍照”,更能“理解”和“決策”,處理復(fù)雜的缺陷分類、變化的場(chǎng)景,是智能化的靈魂。
- 高速、實(shí)時(shí)的數(shù)據(jù)交互:通過(guò)GigE Vision、USB3 Vision、CoaXPress等高速接口,與機(jī)器人控制器、PLC、上位機(jī)進(jìn)行毫秒級(jí)的數(shù)據(jù)通信,實(shí)現(xiàn)視覺(jué)與動(dòng)作的閉環(huán)控制,滿足高速生產(chǎn)線的節(jié)拍要求。
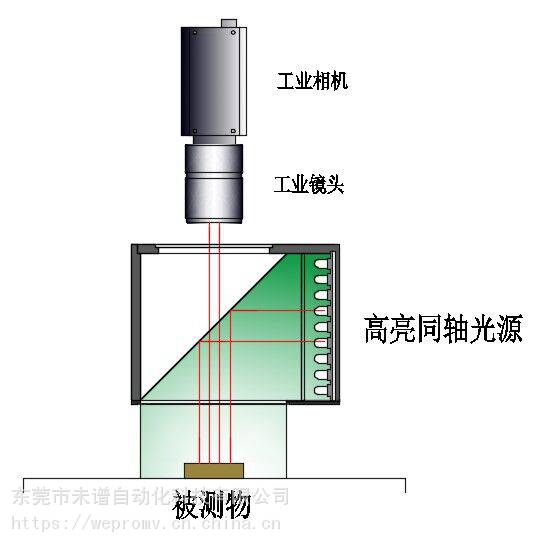
- 靈活、集成的照明系統(tǒng):合適的工業(yè)光源是發(fā)揮相機(jī)性能的“放大器”。根據(jù)檢測(cè)對(duì)象特征(形狀、材質(zhì)、顏色)配備的環(huán)形光、條形光、同軸光、背光等,能突出關(guān)鍵特征,抑制干擾,是保證成像質(zhì)量的關(guān)鍵一環(huán)。
在機(jī)器人自動(dòng)化工廠的宏偉藍(lán)圖中,工業(yè)相機(jī)已從可選的“配件”演變?yōu)椴豢苫蛉钡摹皹?biāo)準(zhǔn)配置”和“核心感官”。一個(gè)高大上的智能工廠,其標(biāo)配的工業(yè)視覺(jué)系統(tǒng)必然是類型多元、3D與2D結(jié)合、軟硬件深度融合、兼具極致性能與超凡可靠性的有機(jī)整體。它不僅是提升效率與質(zhì)量的工具,更是工廠實(shí)現(xiàn)數(shù)字化、網(wǎng)絡(luò)化、智能化轉(zhuǎn)型,邁向工業(yè)4.0的視覺(jué)神經(jīng)中樞。隨著嵌入式AI、高光譜成像等技術(shù)的融合,這雙“智能之眼”將看得更清、懂得更多、反應(yīng)更快,持續(xù)定義智能制造的新高度。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.bsyffe.cn/product/27.html
更新時(shí)間:2026-05-28 03:29:54